Master the F 13 Chord for Guitar
Want a structured chord roadmap instead of jumping between pages?
Go to the full guitar chords tutorial.
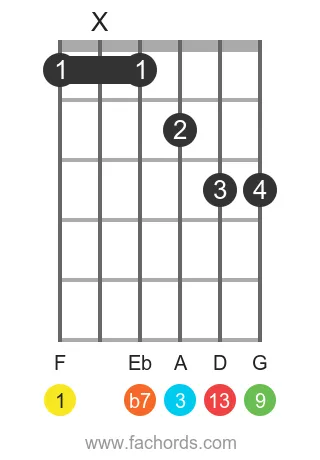
The F 13 chord is a sophisticated extended dominant, meticulously built from specific intervals: 1 (Root), 3 (Major Third), 5 (Perfect Fifth), b7 (Minor Seventh), 9 (Major Ninth), 11 (Perfect Eleventh), and 13 (Major Thirteenth). This intricate structure results in the seven distinct notes F, A, C, Eb, G, Bb, and D. To truly grasp its sound and fingerings, utilize our interactive virtual fretboard to visualize these tones, play back chords and arpeggios, and use real-time mic feedback to accurately check your performance.
Understanding the construction of complex harmonies like the F 13 is key to advanced guitar playing. This chord is a prime illustration of how additional intervals stack upon a fundamental Dominant Chord. If the concept of building chords by stacking intervals is new to you, our detailed guide on Chord Construction provides a solid foundation. Given that 13th chords extend beyond 9ths, exploring Ninth Chords can also deepen your understanding of these rich, extended harmonies.
This page is designed to guide your disciplined practice of the F 13 chord, starting with the interactive tool, then progressing through various chord diagrams from simplest to most complex. Explore its theoretical underpinnings, learn how it's used in songs, and discover its application across different keys to solidify your command of this challenging yet rewarding chord.
Notes of the F 13 chord:
Chord structure of the Dominant Thirteen chord:
F Dominant Thirteen Guitar Chord Diagrams
Position 1
Movable
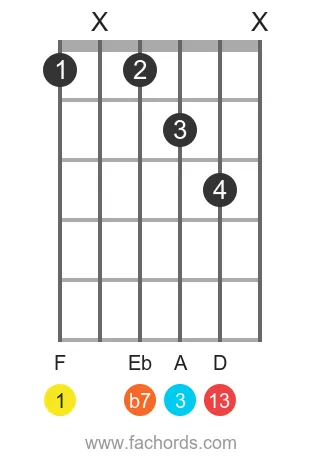
Position 2
Movable
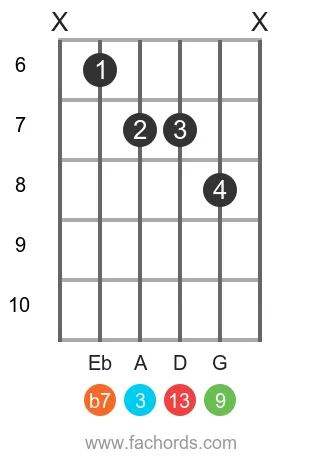
Position 3
Movable
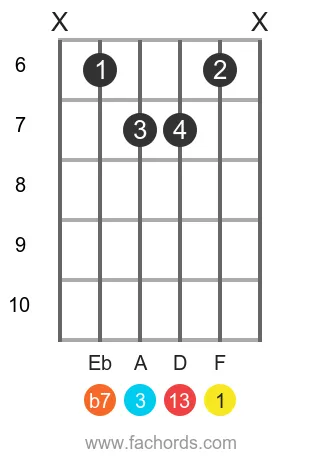
Position 4
Barre
Movable
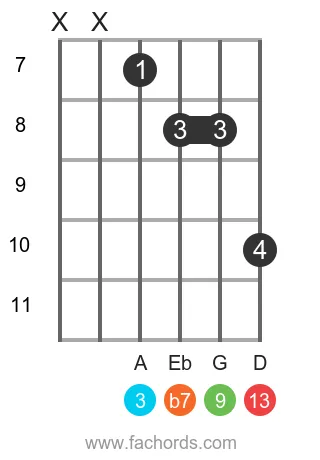
Position 5
Barre
Movable
Position 6
Barre
Movable
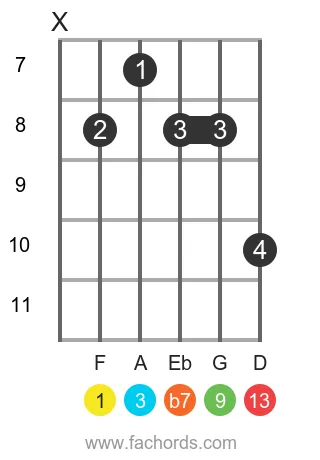
Position 7
Barre
Movable
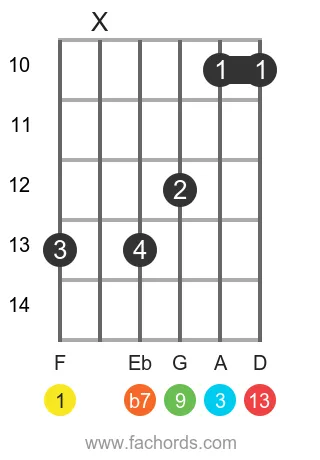
 Find more shapes in our all guitar chords online library. If you
prefer a printable pdf, download
the Free Guitar Chords Chart Pdf
Find more shapes in our all guitar chords online library. If you
prefer a printable pdf, download
the Free Guitar Chords Chart Pdf
You can also use this accessible F13 chord page, with written diagram instructions and screen-reader support for blind users.


Created by
Giancarlo is a musician (teaching guitar since 2000), software engineer, AI consultant and published researcher
FAQ
What notes are included in an F 13 chord?
The F 13 chord is composed of seven distinct notes: F (root), A (major third), C (perfect fifth), Eb (minor seventh), G (major ninth), Bb (perfect eleventh), and D (major thirteenth).
Why is the F 13 chord categorized as a dominant chord?
The F 13 chord is a dominant chord because it contains both a major third (A) and a minor seventh (Eb) relative to its root (F). This specific interval combination gives it the characteristic dominant quality.
What do the numbers 9, 11, and 13 signify in the F 13 chord?
In the F 13 chord, the numbers 9, 11, and 13 refer to specific chord extensions. These represent a Major Ninth (G), a Perfect Eleventh (Bb), and a Major Thirteenth (D) interval, respectively, all measured from the root note F. These notes are added on top of the basic dominant seventh chord (1, 3, 5, b7).
Do I need to play all seven notes of an F 13 chord on the guitar?
While the F 13 chord technically consists of seven notes, guitar voicings often omit certain intervals for playability and clarity. Commonly, the perfect fifth (C) or perfect eleventh (Bb) may be left out to prioritize the essential dominant sound and the higher extensions like the ninth and thirteenth, which define the chord's unique color.
How does an F 13 chord differ from a simpler F7 chord?
An F7 chord includes the root (F), major third (A), perfect fifth (C), and minor seventh (Eb). The F 13 chord, however, extends beyond this by adding the major ninth (G), perfect eleventh (Bb), and major thirteenth (D) intervals. This makes the F 13 a much richer and more complex dominant chord with additional harmonic color.